① 🤖 中国AI企業が次の一手──「GLM-Image」が画像生成AIの常識を変えるか
中国のAI企業であるZ.aiが、オープンソースの新しい画像生成AI「GLM-Image」を発表しました。GLM-Image最大の特徴は、これまで別々に進化してきた「自己回帰モデル(Autoregressive)」と「拡散モデル(Diffusion)」を融合したハイブリッド構造にあります。
近年の画像生成AI市場は、OpenAIのDALL·E、Stability AIのStable Diffusion、Midjourneyなどが主流でしたが、いずれも基本的には拡散モデルが中心です。そんな中、Z.aiは「拡散モデルだけでは限界がある」とし、言語理解に強い自己回帰モデルを組み合わせることで、新たな画像生成アーキテクチャを提案しました。
単なる“中国版画像生成AI”ではなく、「次世代オープンソース画像モデル」として世界の開発者コミュニティから注目を集めています。

② 🧠 GLM-Imageの仕組み──自己回帰と拡散モデルをどう融合したのか
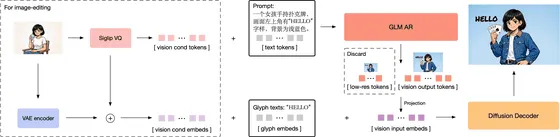
GLM-Imageは、2つの大規模AIモデルを組み合わせた構造になっています。
まず、画像全体の意味理解や構図設計を担うのが、90億パラメータを持つ自己回帰モデル「GLM-4-9B-041」です。そして、その後のディテール生成や質感補完を担うのが、70億パラメータの拡散デコーダーです。
この仕組みにより、「何を描くか」は自己回帰モデルが決定し、「どう美しく描くか」は拡散モデルが仕上げるという役割分担が実現されています。
⚙️ GLM-Imageのアーキテクチャ
- 🧠 自己回帰モデル:90億パラメータ
- 🎨 拡散デコーダー:70億パラメータ
- 💻 合計:約160億パラメータ級
- 🔄 シングルストリームDiT構造採用
- 📚 ベースモデル:GLM-4 + CogView系技術
技術的には、「低周波情報(意味・構図)」を自己回帰で生成し、「高周波情報(質感・細部)」を拡散モデルで補完する仕組みになっています。
③ ✍️ なぜ“文字に強い”画像生成AIが重要なのか
GLM-Imageが特に注目されているのは、画像内の「文字描画(Text Rendering)」性能の高さです。
従来の拡散モデルでは、「東京駅」「SALE 50% OFF」「量子コンピュータ」など文字を含む画像を生成すると、文字が崩れたり意味不明な記号になったりする問題がありました。
これは拡散モデルが“ピクセルとして画像を理解する”ことには強い一方で、“文字の意味”を理解するのが苦手だからです。
GLM-Imageは言語モデル由来の自己回帰部分がテキスト理解を担当するため、複雑な文字情報や専門知識を含む画像生成で高い精度を実現しています。
✨ GLM-Imageが得意な生成タスク
- 📰 広告バナーやポスター制作
- 📖 漫画・吹き出し付きイラスト
- 📊 インフォグラフィック
- 📚 教育コンテンツ画像
- 🧬 科学・医療・工学系ビジュアル
単なる“綺麗な絵”ではなく、“意味が通る画像”を作れる点が大きな差別化ポイントです。

④ 🌍 オープンソース化の意味──中国AIが世界市場へ攻勢
GLM-Imageは、コードと学習済みモデルがGitHubおよびHugging Face上で公開されています。これは、商用レベルの画像生成モデルを完全オープンソースとして公開するという意味で、業界でもインパクトの大きい発表です。
近年、中国のAI企業はオープンモデル戦略を加速させています。
代表例として、
- DeepSeek:高性能LLMを無料公開
- Alibaba:画像生成AI「Tongyi」「Z-Image」公開
- Baidu:ERNIEシリーズ強化
- Zhipu AI:GLMシリーズ展開
中国勢は「クローズドなAPI販売」ではなく、「オープンモデルで世界の開発者を囲い込む」戦略を強めています。
⑤ 🚀 Stable Diffusionの次世代候補になるのか?
GLM-Imageの登場で、画像生成AIの競争軸そのものが変わる可能性があります。
これまでの主流だった拡散モデルは、芸術性や高品質生成には優れていましたが、複雑な命令理解や長文プロンプト、知識ベース生成では限界がありました。
一方、自己回帰モデル単独では高精度でも速度が遅く、計算コストが高いという課題がありました。
GLM-Imageはその両者の長所を統合したことで、次のような市場インパクトが予想されています。
🔮 今後の注目ポイント
- 🎨 Stable Diffusion系との性能比較
- ⚡ 推論速度とGPU負荷
- 💼 商用利用ライセンスの柔軟性
- 🌐 多言語レンダリング精度
- 🇺🇸 米国製AIモデルとの差別化
もしGLM-Imageが安定した商用運用まで実現すれば、「画像生成版DeepSeek」として世界市場に大きな影響を与える可能性があります。
✅ まとめ:中国発GLM-Imageは“画像AIの次の標準”になるかもしれない
GLM-Imageは、自己回帰モデルの「理解力」と拡散モデルの「描写力」を融合した、新しい世代の画像生成AIです。
特に文字描画、知識ベース画像、複雑な指示への忠実性といった分野で、従来モデルの弱点を補う存在として期待されています。
さらにオープンソースで公開されたことで、単なる研究成果ではなく、世界中の開発者が改良・応用できる“次世代インフラ”として成長する可能性もあります。
2026年の画像生成AI競争は、単なる“絵の美しさ”から、“どれだけ意味を理解できるか”へと進化し始めているのかもしれません。
📚 参考・出典
- Z.ai Official Website
- GLM-Image GitHub Repository
- GLM-Image on Hugging Face
- Hugging Face
- Stability AI Official Website
- OpenAI Official Website

