― ウェブサイト運営者が AI クローラーに“利用料”を請求できる新マーケットプレイス

1️⃣ 背景:コンテンツはタダではない
- ChatGPT など生成 AI の急拡大で、大量のウェブ記事・ブログ・論文が無許可で学習データに
- Google 検索の「AI 概要」機能も相まって、サイト訪問数が激減──広告収益が危機に
- Cloudflare のマシュー・プリンス CEO は「これはパブリッシャーの“存在危機”」と警鐘を鳴らし、AI クローラー対策ツールを段階的に公開
| 既存ツール | 主な機能 |
|---|---|
| AI Labyrinth | 不正ボットを“迷路”へ誘導しクロールを妨害 |
| AI Audit | どの AI クローラーが来ているかを可視化・制御 |
2️⃣ 新サービス「Pay per Crawl」とは?
“無料 or ブロック”しかなかった二者択一に「第3の選択肢」を追加!
| 概要 | 内容 |
|---|---|
| 🎯 目的 | コンテンツ所有者が クローラー単位で課金 or 拒否 を選択 |
| 🔑 コア技術 | HTTP ステータスコード + Cloudflare WAF + 認証トークン |
| 💸 料金設定 | ドメイン全体/パス単位/1 リクエスト単位 … など柔軟に指定 |
| 🤝 決済 | Cloudflare 経由で自動精算(詳細は今後アナウンス) |
❶ 無料で許可 ❷ 料金を提示して許可 ❸ 完全拒否
――三つのモードを リクエストごと に振り分けられるのが特徴です。

3️⃣ なぜ“マーケットプレイス”が必要なのか?
| 課題 | Pay per Crawl が提供する解決策 |
|---|---|
| AI 企業が勝手にスクレイピング | 利用料を支払わせる ことで“データの対価”を可視化 |
| 一律ブロックは自社の露出も下げる | 制御の細分化 により、検索エンジン等は許可し一部 AI だけ課金も可能 |
| 法的手段は時間もコストも高い | HTTP レベルで 技術的・即時的に実装 できる仕組み |
プリンス CEO は今回の発表を「Content Independence Day(コンテンツ独立記念日)」と呼び、
「AI 企業のイノベーションを阻害せず、クリエイターの“権利と収益”を取り戻す」
と強調しています。
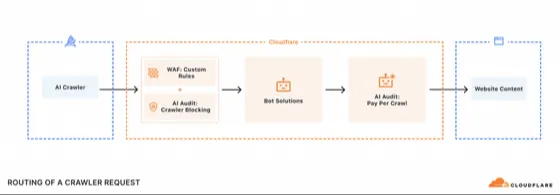
4️⃣ 導入イメージ(簡易フロー)
- ドメイン管理画面で 「Pay per Crawl」を有効化
- 料金 or 拒否ポリシーを パス / User‑Agent / IP などで設定
- AI ボットが来訪 → Cloudflare WAF が判定
- ポリシーに従い
- 💸 支払いページを返す → 成立後コンテンツ配信
- 🚫 支払い拒否なら 403 / 451 などでブロック
- 月次で利用料を集計 → クリエイターへ還元
5️⃣ 今後の論点・展望
| 注目ポイント | 詳細 |
|---|---|
| 💳 価格形成 | 業界横断の“相場”がどう決まるか?大手メディア vs 個人ブログで差は? |
| 📊 検索エンジンとの関係 | Google・Bing など基本インデックスクローラーは無料許可? |
| 🛡 悪質ボット対策 | 認証回避や User‑Agent 偽装などをどう防ぐか |
| 🌐 オープンウェブの理念 | クローラー課金が“情報格差”を広げる懸念も。オープンアクセス文化と収益化のバランス |
✍️ まとめ
- Cloudflare は 「タダ乗りか全面ブロックか」 の硬直状態に、“課金という第三の選択肢” を提示
- コンテンツホルダーは 収益機会の創出、AI 企業は 合法的なデータ利用 が可能に
- ウェブのエコシステムを揺るがす一手。クリエイターと AI の共存ルール作り が本格化しそうです⚖️

