Alibabaが開発した画像認識AI**「Qwen3-VL」に、待望の軽量版モデルが登場しました。
その名も「Qwen3-VL-4B」および「Qwen3-VL-8B」。
これらの新モデルは、従来版と同じ機能を保持しながらもVRAM使用量を大幅に削減**し、ローカル環境でも実用的なパフォーマンスを実現しています✨
📄 出典:

⚙️ 軽量でもフル機能搭載、性能はQwen2.5-VL-72B級
新たに公開されたQwen3-VL-4B/8Bは、上位モデルと同じ画像理解・文章生成・マルチモーダル推論機能を維持しています。
にもかかわらず、必要VRAMは半分以下。
それでいて、従来の大型モデルQwen2.5-VL-72Bに匹敵する精度を発揮します。
💡 対応タスクは以下の通り:
- 🧮 STEM(数式・科学図表の理解)
- 👁️ 画像理解(VQA)
- 🧾 OCR(文字認識)
- 🎞️ 動画理解・キャプション生成
- 🤖 エージェントタスク(思考+行動系AI)
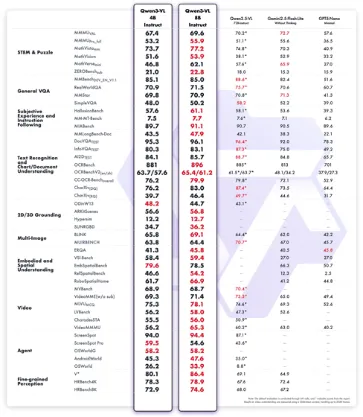
Qwen3-VLは、Gemini 2.5 Flash LiteやGPT-5 Nanoといった競合を上回るスコアを記録しており、軽量モデルながら研究・開発用途でも十分な実力を持っています。
💻 Nexa SDKを使ってローカル環境に導入
今回は、Qwen3-VL-8B-Thinkingモデルを実際にローカルPCへ導入してテストしました。
導入は**「Nexa SDK」**を利用します。Nexa SDKはWindows、Linux、macOSに対応しており、公式サイトから無料で入手できます。
🧩 手順概要
- Nexa SDK公式サイト からSDKをダウンロード
- Qwenアカウントでログイン
- アクセストークンを取得
- PowerShellで以下のように設定:
nxa auth set <your_access_token>
これで準備完了。
あとは画像ファイルを指定して、プロンプトを入力するだけで画像認識タスクを実行できます。
ログインが必要なのでログインします。
アクセストークンを取得します。
アクセストークンが表示されるので、これをコピーしておきます。
🍕 実際に試してみた:画像認識精度をチェック
テストでは、ピザの写真を入力して画像認識能力を評価しました。
🧠 結果:
- 写真内のピザ、皿、ボトル、メニュー用紙などを正確に検出
- 「串」を「スプーン」と誤認する軽微なミスはあったものの、
構図の理解力と細部の抽出精度は非常に高い - 日本語文字・数字のOCRも良好
視覚的な理解だけでなく、テキスト情報の抽出精度も高水準。
特に、細かい被写体の形状や物体関係まで識別している点に驚かされました。
🧠 軽量でも実用レベルの性能を発揮
今回のテスト機材は以下の構成:
| 項目 | 内容 |
|---|---|
| CPU | Intel(R) Core(TM) Ultra 5 125U |
| メモリ | 64GB |
| GPU | NVIDIA GeForce RTX 2060 SUPER (8GB VRAM) |
結果、4Bモデルではスムーズに動作。
推論中のVRAM使用量も非常に低く、8GBクラスのGPUでも快適に利用できました。
🧩 Qwen3-VL-4B/8Bは、
「高性能AIをローカルで手軽に使いたい」
という開発者や研究者に理想的な選択肢です。
🚀 思考型AIにも対応、開発用途に最適
Qwen3-VL-4B/8Bは、従来の画像理解モデルに加え、**“Thinking(思考)バリアント”**も提供されています。
これにより、単純な画像分類だけでなく、推論・質問応答・文脈理解など、より高次な認知タスクにも対応可能。
さらに、Nexa SDK経由で簡単にアプリケーション統合できるため、
Webアプリやロボット制御、画像検索サービスなどにも応用できます。
🧩 まとめ:Qwen3-VL軽量版は“ローカルAI時代”の主役
AlibabaのQwen3-VLシリーズは、すでに世界トップレベルのマルチモーダルAIとして高い評価を得ています。
今回の4B/8B軽量版は、
- 小規模GPUでも動作可能
- 高精度な画像理解を維持
- 思考型AIまで搭載
という点で、個人・開発者・中小企業のAI導入を一気に現実的にするモデルです。
💬 「VRAMが足りないからローカルで動かせない」
──そんな時代はもう終わりです。

