AIによってテキストから動画を自動生成する時代が、ついに誰でも手の届くものになりました。
2025年10月、無料&オープンソースの動画生成AIモデル「Ovi」が公開され、
「テキスト」または「テキスト+画像」から5秒のショート動画と音声を同時生成できると話題を集めています。
GitHub上でモデルが完全公開されており、環境を構築すれば誰でも無料で利用可能です。
開発したのはAI対話サービスで知られるcharacter.ai。
AI動画生成分野における“革命的モデル”として注目されています。

🧠Oviとは?テキストだけで映像と音声を同時生成できる次世代AI
Oviは、テキストや画像を入力するだけで自動的に映像と音声を生成するオープンソースAIモデルです。
動画の長さは最大5秒、フレームレートは24fps、解像度は最大720×720。
さらにアップスケーリング機能により、より高解像度な出力も可能です。
🧩 主な特徴:
- ✅ テキストだけでも動画生成可能
- 🖼️ 画像+テキスト入力にも対応(条件付き生成)
- 🔉 音声も同時生成(ナレーション・環境音付き)
- 🧮 オープンソース公開(GitHub)
- ⚡ 無料で利用可能(ローカル実行時)
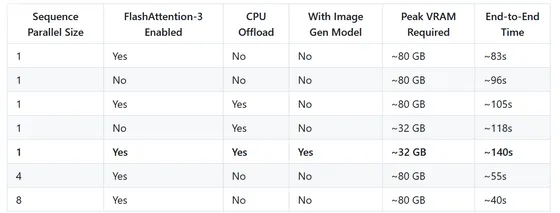
実行環境としてはGPUメモリ32GB以上が推奨され、
FP8量子化モデルでは24GBメモリでも動作可能。
ハイエンドGPU環境であれば、5秒の動画を40秒未満で生成できる高速処理を実現しています。
⚙️実際の動作スピード:RTX 5090で約4〜5分
Oviはローカルでの利用が基本ですが、wavespeed.aiやHugging Face Spacesでも試すことが可能です。
これらのプラットフォームではクレジット制が採用されていますが、Ovi自体は無料・オープンソースで提供されています。
実際に試したユーザーの声によると:
「1週間ほど使ってみたが本当に素晴らしい。他のAI動画ツールのように、良いプロンプトでも失敗作が出ることもあるが、時間をかければ“使える映像”が得られる。
RTX 5090を使用して、5秒の動画生成に約4〜5分かかった。」
生成結果は90年代テレビのような独特の質感を持つものもあり、
その“アナログ感”が逆にリアルだと評価する声も多く挙がっています。
🔊「映像+音声」を同時に生み出す秘密:50億パラメータの音声ブランチ
Oviの最大の革新は、映像と音声を同時に生成できる設計です。
開発元のcharacter.aiは、自社独自の音声データセットを使用し、
約50億パラメータ(5B)規模の音声ブランチをゼロから設計・学習しました。
これにより、Oviは動画の映像内容に合わせて音声を生成し、
まるで“1本の完成された動画”のような出力を可能にしています。
また今後は、より高解像度のデータによるファインチューニングを行い、
より長尺の動画生成にも対応する予定だと発表されています。
🧩Oviの仕組みと生成プロセス
Oviの生成は、50ステップのノイズ除去(denoising)を経て動画を出力する仕組み。
121フレーム(=5秒×24fps)の動画を作成する場合でも、
高効率なノイズ推定アルゴリズムによって処理がスムーズに進みます。
⚙️ 生成プロセスの流れ
- テキスト入力(例:「A cat walking in the rain」)
- 拡散モデルによる映像生成
- 音声ブランチによる音の自動生成
- 最終的に音付きMP4として出力
この一連の処理が40〜300秒以内で完結するという驚異的なスピードを実現しています。
🚀動画生成AIの“民主化”が始まった
OpenAIの「Sora」やGoogleの「Veo」といった動画生成AIは、
どれも商用利用やアクセス制限が厳しい一方で、
Oviは完全オープンソースで、個人でも自由に研究・開発・改変が可能。
これはAI動画生成の分野において、“民主化(Democratization)”を象徴する出来事です。
既存の商用AIに匹敵する出力を、誰でも自分のマシンで再現できるようになりました。
🔚まとめ:Oviは「AIクリエイター時代」の扉を開く
Oviの登場は、AIによる映像制作の敷居を一気に下げたといえます。
無料で、しかもオープンソース。
テキストを入力するだけで、映像と音声が一体となった作品を瞬時に生成できる。
動画制作が専門的なスキルではなく、
“アイデアとテキスト”だけで表現できる時代が、すぐそこまで来ています。
✨
Oviは単なるAIツールではなく、「創造力の加速装置」だ。
— クリエイターコミュニティより

